Physicists are confident that a quantum computer will soon outperform the world’s most powerful supercomputer. To prove it, they have developed a test that will pit one against the other.
Twice a year, the TOP500 project publishes a ranking of the world’s most powerful computers. The list is eagerly awaited and hugely influential. Global superpowers compete to dominate the rankings, and at the time of writing China looms largest, with 229 devices on the list.
The US has just 121, but this includes the world’s most powerful: the Summit supercomputer at Oak Ridge National Laboratory in Tennessee, which was clocked at 143 petaflops (143 thousand million million floating point operations per second).
The ranking is determined by a benchmarking program called Linpack, which is a collection of Fortran subroutines that solve a range of linear equations. The time taken to solve the equations is a measure of the computer’s speed.
There is no shortage of controversy over this choice of benchmark. Computer architectures are usually optimized to solve specific problems, and many of these are very different from the Linpack challenge. Quantum computers, for example, are entirely unsuited to solving these kinds of problems.
Today we get an answer thanks to the work of Benjamin Villalonga at the Quantum Artificial Intelligence Lab at NASA Ames Research Center in Mountain View, California, and a group of colleagues who have developed a benchmarking test that works on both classical and quantum devices. In this way, it is possible to compare their performance.
What’s more, the team has used the new test to put the Summit, the world’s most powerful supercomputer, through its paces running at 281 petaflops. The result is the benchmark that quantum computers must beat to finally establish their supremacy in the rankings.
Finding a good measure of quantum computing power is no easy task. For a start, computer scientists have long known that quantum computers can outperform their classical counterparts in only a limited number of highly specialized tasks. And even then, no quantum computer is currently powerful enough to perform any of them particularly well because, for example, they are incapable of error correction.
So Villalonga and co looked for a much more fundamental test of quantum computing power that would work equally well for today’s primitive devices and tomorrow’s more advanced quantum machines, and could also be simulated on classical machines.
Their chosen problem is to simulate the evolution of quantum chaos using random quantum circuits. Simple quantum computers can do this because the process does not require powerful error correction, and it is relatively straightforward to filter out results that have been overwhelmed by noise.
It is also straightforward for classical machines to simulate quantum chaos. But the classical computing power required to do this rises exponentially with the number of qubits involved.
Two years ago, physicists determined that quantum computers with at least 50 qubits should achieve quantum supremacy over a classical supercomputer at that time.
But the goalposts are constantly moving as supercomputers are upgraded. For example, Summit is capable of significantly more petaflops now than in the last ranking in November, when it tipped the scales at 143 petaflops. Indeed, Oak Ridge National Labs this week unveiled plans to build a 1.5-exaflop machine by 2021. So being able to continually benchmark these machines against the emerging quantum computers is increasingly important.
Researchers at NASA and Google have created an algorithm called qFlex that simulate random quantum circuits on a classical machine. Last year, they showed that qFlex could simulate and benchmark the performance of a Google quantum computer called Bristlecone, which has 72 qubits. To do this, they used a supercomputer at NASA Ames with 20 petaflops of number-crunching power.
Now they’ve shown that the Summit supercomputer can simulate the performance of a much larger quantum device. “On Summit, we were able to achieve a sustained performance of 281 Pflop/s (single precision) over the entire supercomputer, simulating circuits of 49 and 121 qubits,” they say.
This 121 qubits is beyond the capability of any existing quantum computer. So classical computers remain a hair’s breadth ahead in the rankings.
But this is a race they are destined to lose. Plans are already afoot to build quantum computers with 100+ qubits within the next few years. And as quantum capabilities accelerate, the challenge of building ever more powerful classical machines is already coming up against the buffers.
The limiting factor for new machines is no longer the hardware but the power available to keep them humming. The Summit machine already requires a 14-megawatt power supply. That’s enough to light up an entire a medium-sized town. “To scale such a system by 10x would require 140 MW of power, which would be prohibitively expensive,” say Villalonga and co.
By contrast, quantum computers are frugal. Their main power requirement is the cooling for superconducting components. So a 72-qubit computer like Google’s Bristlecone, for example, requires about 14 kw. “Even as qubit systems scale up, this amount is unlikely to significantly grow,” say Villalonga and co.
So in the efficiency rankings, quantum computers are destined to wipe the floor with their classical counterparts sooner rather than later.
One way or another, quantum supremacy is coming. If this work is anything to go by, the benchmark that will prove it is likely to be qFlex.
Ref: arxiv.org/abs/1905.00444 : Establishing the Quantum Supremacy Frontier with a 281 Pflop/s Simulation
He revealed details about the company’s new rocket, engine, and lunar lander at a private event in Washington, DC, May 9.
Behind curtain number one … Jeff Bezos unveiled Blue Moon, the company’s lunar lander that has been in the works for the past three years. It will be able to land a 6.5-metric-ton payload on the moon’s surface. Watch Blue Origin’s video rendering of what Blue Moon’s lunar landing could look like here.
Who’s hitching a ride? The company announced a number of customers that will fly on Blue Moon, including Airbus, MIT, Johns Hopkins, and Arizona State University.
How are they getting there?New Glenn. This is by far the biggest rocket Blue Origin has ever built. The size will allow the massive Blue Moon lander to fit inside. It will have fewer weather constraints and will be rated to carry humans from the start. As with New Shepard, the company’s suborbital rocket, as well as SpaceX’s rockets, the first stage will be reusable, landing again after completing its mission. The first launch is targeted for 2021.
The new engine: Blue Origin also announced that the new BE-7 engine, which packs 10,000 pounds of thrust, will undergo its first hot fire test this year. This engine will propel Blue Moon
Facebook has been beset by scandals over the last year and many believe that nothing will change until its founder and CEO is gone.
A petition has been launched with one simple objective: to force Mark Zuckerberg to resign as CEO of Facebook.
The campaign group behind it, Fight for the Future, says that although there’s no “silver bullet” to “fix” Facebook, the company cannot address its underlying problems while Zuckerberg remains in charge.
The petition is highly unlikely to succeed, of course. It’s hard to imagine Zuckerberg stepping down voluntarily. And there’s not much Facebook’s board can do either, even if they wanted to. Zuckerberg controls about 60% of all voting shares in Facebook. He’s pretty much untouchable, both as CEO and as board chairman. Despite near-weekly scandals, the company is still growing, and it’s one of the most profitable business ventures in human history.
(Another potential solution, as described in a piece in the New York Timeswritten by one of Facebook’s cofounders, is to break the company up and implement new data privacy regulations in the US.)
Need a reminder as to why everyone is so angry with Facebook and Mark Zuckerberg anyway? Here’s a handy cut-out-and-keep list of just some of the most significant scandals involving the tech giant over the last year or so. (Not to mention all the wider problems of fake news or echo chambers or the decimation of the media. Or dodgy PR practices.)
The high-impact one
Back in March 2018, a whistleblower revealed that political consultancy Cambridge Analytica had collected private information from more than 87 million Facebook profiles without the users’ consent. Facebook let third parties scrape data from applications: in Cambridge Analytica’s case, a personality quiz developed by a Cambridge University academic, Aleksandr Kogan. Mark Zuckerberg responded by admitting “we made mistakes” and promising to restrict data sharing with third-party apps in the future.
In September 2018, Facebook admitted that 50 million users had had their personal information exposed by a hack on its systems. The number was later revised down to 30 million, which still makes it the biggest breach in Facebook’s history.
In March 2019 it turned out Facebook had been storing up to 600 million users’ passwords insecurely since 2012. Just days later, we learned that half a billion Facebook records had been left exposed on the public internet.
The discriminatory advertising practices
Facebook’s ad-serving algorithm automatically discriminates by gender and race, even when no one tells it to. Advertisers can also explicitly discriminateagainst certain areas when showing housing ads on Facebook, even though it’s illegal. Facebook has known about this problem since 2016. It still hasn’t fixed it.
The dodgy data deals
Facebook gave over 150 companies more intrusive access to users’ data than previously revealed, via special partnerships. We learned a bit more about this, and other dodgy data practices, in a cache of documents seized by the UK Parliament in November 2018. Facebook expects to be fined up to $5 billion for this and other instances of malpractice.
The vehicle for hate speech
The Christchurch, New Zealand, shooter used Facebook to live-stream his murder of 50 people. The broadcast was up for 20 minutes before any action was taken. We’re still waiting to hear what, if anything, Facebook will do about this issue (for example, it could choose to end its “Facebook Live” feature). It’s well established now that Facebook can help to fuel violence in the real world. But any response from Facebook has been piecemeal. It’s also a reminder of just how much power we’ve given Facebook (and its low-paid moderators) to decide what is and isn’t acceptable.
We’ve been wasting our processing power to train neural networks that are ten times too big.
Neural networks are the core software of deep learning. Even though they’re so widespread, however, they’re really poorly understood. Researchers have observed their emergent properties without actually understanding why they work the way they do.
Now a new paper out of MIT has taken a major step toward answering this question. And in the process the researchers have made a simple but dramatic discovery: we’ve been using neural networks far bigger than we actually need. In some cases they’re 10—even 100—times bigger, so training them costs us orders of magnitude more time and computational power than necessary.
Put another way, within every neural network exists a far smaller one that can be trained to achieve the same performance as its oversize parent. This isn’t just exciting news for AI researchers. The finding has the potential to unlock new applications—some of which we can’t yet fathom—that could improve our day-to-day lives. More on that later.
But first, let’s dive into how neural networks work to understand why this is possible.
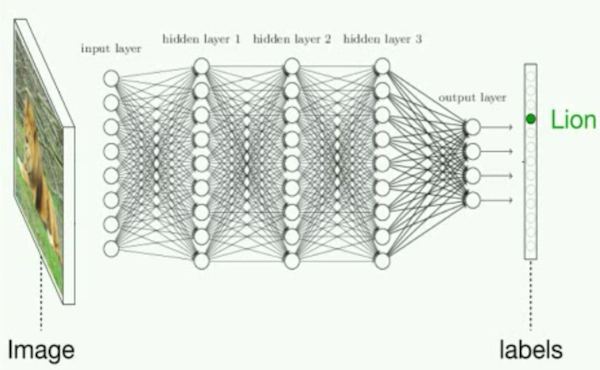
A diagram of a neural network learning to recognize a lion.
JEFF CLUNE/SCREENSHOT
How neural networks work
You may have seen neural networks depicted in diagrams like the one above: they’re composed of stacked layers of simple computational nodes that are connected in order to compute patterns in data.
The connections are what’s important. Before a neural network is trained, these connections are assigned random values between 0 and 1 that represent their intensity. (This is called the “initialization” process.) During training, as the network is fed a series of, say, animal photos, it tweaks and tunes those intensities—sort of like the way your brain strengthens or weakens different neuron connections as you accumulate experience and knowledge. After training, the final connection intensities are then used in perpetuity to recognize animals in new photos.
While the mechanics of neural networks are well understood, the reason they work the way they do has remained a mystery. Through lots of experimentation, however, researchers have observed two properties of neural networks that have proved useful.
Observation #1. When a network is initialized before the training process, there’s always some likelihood that the randomly assigned connection strengths end up in an untrainable configuration. In other words, no matter how many animal photos you feed the neural network, it won’t achieve a decent performance, and you just have to reinitialize it to a new configuration. The larger the network (the more layers and nodes it has), the less likely that is. Whereas a tiny neural network may be trainable in only one of every five initializations, a larger network may be trainable in four of every five. Again, why this happens had been a mystery, but that’s why researchers typically use very large networks for their deep-learning tasks. They want to increase their chances of achieving a successful model.
Observation #2. The consequence is that a neural network usually starts off bigger than it needs to be. Once it’s done training, typically only a fraction of its connections remain strong, while the others end up pretty weak—so weak that you can actually delete, or “prune,” them without affecting the network’s performance.
For many years now, researchers have exploited this second observation to shrink their networks after training to lower the time and computational costs involved in running them. But no one thought it was possible to shrink their networks before training. It was assumed that you had to start with an oversize network and the training process had to run its course in order to separate the relevant connections from the irrelevant ones.
Jonathan Frankle, the MIT PhD student who coauthored the paper, questioned that assumption. “If you need way fewer connections than what you started with,” he says, “why can’t we just train the smaller network without the extra connections?” Turns out you can.
Michael Carbin (left) and Jonathan Frankle (right), the authors of the paper.
JASON DORFMAN, MIT CSAIL
The lottery ticket hypothesis
The discovery hinges on the reality that the random connection strengths assigned during initialization aren’t, in fact, random in their consequences: they predispose different parts of the network to fail or succeed before training even happens. Put another way, the initial configuration influences which final configuration the network will arrive at.
By focusing on this idea, the researchers found that if you prune an oversize network after training, you can actually reuse the resultant smaller network to train on new data and preserve high performance—as long as you reset each connection within this downsized network back to its initial strength.
From this finding, Frankle and his coauthor Michael Carbin, an assistant professor at MIT, propose what they call the “lottery ticket hypothesis.” When you randomly initialize a neural network’s connection strengths, it’s almost like buying a bag of lottery tickets. Within your bag, you hope, is a winning ticket—i.e., an initial configuration that will be easy to train and result in a successful model.
This also explains why observation #1 holds true. Starting with a larger network is like buying more lottery tickets. You’re not increasing the amount of power that you’re throwing at your deep-learning problem; you’re simply increasing the likelihood that you will have a winning configuration. Once you find the winning configuration, you should be able to reuse it again and again, rather than continue to replay the lottery.
Next steps
This raises a lot of questions. First, how do you find the winning ticket? In their paper, Frankle and Carbin took a brute-force approach of training and pruning an oversize network with one data set to extract the winning ticket for another data set. In theory, there should be much more efficient ways of finding—or even designing—a winning configuration from the start.
Second, what are the training limits of a winning configuration? Presumably, different kinds of data and different deep-learning tasks would require different configurations.
Third, what is the smallest possible neural network that you can get away with while still achieving high performance? Frankle found that through an iterative training and pruning process, he was able to consistently reduce the starting network to between 10% and 20% of its original size. But he thinks there’s a chance for it to be even smaller.
Already, many research teams within the AI community have begun to conduct follow-up work. A researcher at Princeton recently teased the results of a forthcoming paper addressing the second question. A team at Uber also published a new paper on several experiments investigating the nature of the metaphorical lottery tickets. Most surprising, they found that once a winning configuration has been found, it already achieves significantly better performance than the original untrained oversize network before any training whatsoever. In other words, the act of pruning a network to extract a winning configuration is itself an important method of training.
Neural network nirvana
Frankle imagines a future where the research community will have an open-source database of all the different configurations they’ve found, with descriptions for what tasks they’re good for. He jokingly calls this “neural network nirvana.” He believes it would dramatically accelerate and democratize AI research by lowering the cost and speed of training, and by allowing people without giant data servers to do this work directly on small laptops or even mobile phones.
It could also change the nature of AI applications. If you can train a neural network locally on a device instead of in the cloud, you can improve the speed of the training process and the security of the data. Imagine a machine-learning-based medical device, for example, that could improve itself through use without needing to send patient data to Google’s or Amazon’s servers.
“We’re constantly bumping up against the edge of what we can train,” says Jason Yosinski, a founding member of Uber AI Labs who coauthored the follow-up Uber paper, “meaning the biggest networks you can fit on a GPU or the longest we can tolerate waiting before we get a result back.” If researchers could figure out how to identify winning configurations from the get-go, it would reduce the size of neural networks by a factor of 10, even 100. The ceiling of possibility would dramatically increase, opening a new world of potential uses.
The first known case of humans going to court over investment losses triggered by autonomous machines will test the limits of liability.
Robots are getting more humanoid every day, but they still can’t be sued.
So a Hong Kong tycoon is doing the next best thing. He’s going after the salesman who persuaded him to entrust a chunk of his fortune to the supercomputer whose trades cost him more than $20 million.
The case pits Samathur Li Kin-kan, whose father is a major investor in Shaftesbury Plc, which owns much of London’s Chinatown, Covent Garden and Carnaby Street, against Raffaele Costa, who has spent much of his career selling investment funds for the likes of Man Group Plc and GLG Partners Inc. It’s the first-known instance of humans going to court over investment losses triggered by autonomous machines and throws the spotlight on the “black box” problem: If people don’t know how the computer is making decisions, who’s responsible when things go wrong?
“People tend to assume that algorithms are faster and better decision-makers than human traders,” said Mark Lemley, a law professor at Stanford University who directs the university’s Law, Science and Technology program. “That may often be true, but when it’s not, or when they quickly go astray, investors want someone to blame.”
Raffaele Costa
Photographer: Andreas Rentz/Getty Images
The timeline leading up to the legal battle was drawn from filings to the commercial court in London where the trial is scheduled to begin next April. It all started over lunch at a Dubai restaurant on March 19, 2017. It was the first time 45-year-old Li, met Costa, the 49-year-old Italian who’s often known by peers in the industry as “Captain Magic.” During their meal, Costa described a robot hedge fund his company London-based Tyndaris Investments would soon offer to manage money entirely using AI, or artificial intelligence.
Developed by Austria-based AI company 42.cx, the supercomputer named K1 would comb through online sources like real-time news and social media to gauge investor sentiment and make predictions on U.S. stock futures. It would then send instructions to a broker to execute trades, adjusting its strategy over time based on what it had learned.
The idea of a fully automated money manager inspired Li instantly. He met Costa for dinner three days later, saying in an e-mail beforehand that the AI fund “is exactly my kind of thing.”
Over the following months, Costa shared simulations with Li showing K1 making double-digit returns, although the two now dispute the thoroughness of the back-testing. Li eventually let K1 manage $2.5 billion—$250 million of his own cash and the rest leverage from Citigroup Inc. The plan was to double that over time.
But Li’s affection for K1 waned almost as soon as the computer started trading in late 2017. By February 2018, it was regularly losing money, including over $20 million in a single day—Feb. 14—due to a stop-loss order Li’s lawyers argue wouldn’t have been triggered if K1 was as sophisticated as Costa led him to believe.
Li is now suing Tyndaris for about $23 million for allegedly exaggerating what the supercomputer could do. Lawyers for Tyndaris, which is suing Li for $3 million in unpaid fees, deny that Costa overplayed K1’s capabilities. They say he was never guaranteed the AI strategy would make money.
Sarah McAtominey, a lawyer representing Li’s investment company that is suing Tyndaris, declined to comment on his behalf. Rob White, a spokesman for Tyndaris, declined to make Costa available for interview.
The legal battle is a sign of what’s in store as AI is incorporated into all facets of life, from self-driving cars to virtual assistants. When the technology misfires, where the blame lies is open to interpretation. In March, U.S. criminal prosecutors let Uber Technologies Inc. off the hook for the death of a 49-year-old pedestrian killed by one of its autonomous cars.
Robot Investors
AI hedge fund managers are beating human peers, but not stock benchmarks
Source: Eurekahedge, Hedge Fund Research, Inc., Bloomberg
2019 gains through March for every $100 invested in 2014; S&P 500 returns are with dividends reinvested; *HFRI Fund Weighted Composite Index
In the hedge fund world, pursuing AI has become a matter of necessity after years of underperformance by human managers. Quantitative investors—computers designed to identify and execute trades—are already popular. More rare are pure AI funds that automatically learn and improve from experience rather than being explicitly programmed. Once an AI develops a mind of its own, even its creators won’t understand why it makes the decisions it makes.
“You might be in a position where you just can’t explain why you are holding a position,” said Anthony Todd, the co-founder of London-based Aspect Capital, which is experimenting with AI strategies before letting them invest clients’ cash. “One of our concerns about the application of machine-learning-type techniques is that you are losing any explicit hypothesis about market behavior.”
Li’s lawyers argue Costa won his trust by hyping up the qualifications of the technicians building K1’s algorithm, saying, for instance, they were involved in Deep Blue, the chess-playing computer designed by IBM Corp. that signaled the dawn of the AI era when it beat the world champion in 1997. Tyndaris declined to answer Bloomberg questions on this claim, which was made in one of Li’s more-recent filings.
Garry Kasparov plays against IBM’s Deep Blue computer in 1997.
Photographer: Stan Honda/AFP via Getty Images
Speaking to Bloomberg, 42.cx founder Daniel Mattes said none of the computer scientists advising him were involved with Deep Blue, but one, Vladimir Arlazarov, developed a 1960s chess program in the Soviet Union known as Kaissa. He acknowledged that experience may not be entirely relevant to investing. Algorithms have gotten really good at beating humans in games because there are clear rules that can be simulated, something stock markets decidedly lack. Arlazarov told Bloomberg that he did give Mattes general advice but didn’t work on K1 specifically.
Inspired by a 2015 European Central Bank study measuring investor sentiment on Twitter, 42.cx created software that could generate sentiment signals, said Mattes, who recently agreed to pay $17 million to the U.S. Securities and Exchange Commission to settle charges of defrauding investors at his mobile-payments company, Jumio Inc., earlier this decade. Whether and how to act on those signals was up to Tyndaris, he said.
“It’s a beautiful piece of software that was written,” Mattes said by phone. “The signals we have been provided have a strong scientific foundation. I think we did a pretty decent job. I know I can detect sentiment. I’m not a trader.”
There’s a lot of back and forth in court papers over whether Li was misled about K1’s capacities. For instance, the machine generated a single trade in the morning if it deciphered a clear sentiment signal, whereas Li claims he was under the impression it would make trades at optimal times during the day. In rebuttal, Costa’s lawyers say he told Li that buying or selling futures based on multiple trading signals was an eventual ambition, but wouldn’t happen right away.
For days, K1 made no trades at all because it didn’t identify a strong enough trend. In one message to Costa, Li complained that K1 sat back while taking adverse movements “on the chin, hoping that it won’t strike stop loss.” A stop loss is a pre-set level at which a broker will sell to limit the damage when prices suddenly fall.
That’s what happened on Valentine’s Day 2018. In the morning, K1 placed an order with its broker, Goldman Sachs Group Inc., for $1.5 billion of S&P 500 futures, predicting the index would gain. It went in the opposite direction when data showed U.S. inflation had risen more quickly than expected, triggering K1’s 1.4 percent stop-loss and leaving the fund $20.5 million poorer. But the S&P rebounded within hours, something Li’s lawyers argue shows K1’s stop-loss threshold for the day was “crude and inappropriate.”
Li claims he was told K1 would use its own “deep-learning capability” daily to determine an appropriate stop loss based on market factors like volatility. Costa denies saying this and claims he told Li the level would be set by humans.
In his interview, Mattes said K1 wasn’t designed to decide on stop losses at all—only to generate two types of sentiment signals: a general one that Tyndaris could have used to enter a position and a dynamic one that it could have used to exit or change a position. While Tyndaris also marketed a K1-driven fund to other investors, a spokesman declined to comment on whether the fund had ever managed money. Any reference to the supercomputer was removed from its website last month.
Investors like Marcus Storr say they’re wary when AI fund marketers come knocking, especially considering funds incorporating AI into their core strategy made less than half the returns of the S&P 500 in the three years to 2018, according to Eurekahedge AI Hedge Fund Index data.
“We can’t judge the codes,” said Storr, who decides on hedge fund investments for Bad Homburg, Germany-based Feri Trust GmbH. “For us it then comes down to judging the setups and research capacity.”
But what happens when autonomous chatbots are used by companies to sell products to customers? Even suing the salesperson may not be possible, added Karishma Paroha, a London-based lawyer at Kennedys who specializes in product liability.
“Misrepresentation is about what a person said to you,” she said. “What happens when we’re not being sold to by a human?”